2022年8月,在举办的USENIX安全研讨会(USENIX Security Symposium)中,复旦大学计算机科学技术学院的杨珉教授和张谧教授等人率先提出基于文本风格的隐式NLP模型后门攻击技术,能有效绕过几乎所有已知后门检测方法。
近年来,深度文本表征模型已广泛应用于舆情分析、内容安全、搜索引擎等实际应用场景,很大程度影响着网络生态安全。随着谷歌、OpenAI、百度等大型IT公司发布了多种预训练深度文本表征模型(如BERT、GPT-2等),从公开模型仓库下载、整合并部署预训练模型逐步成为下游服务商青睐的主要应用范式。然而,基于对深度文本表征模型的隐式后门行为进行检测,项目组发现潜在攻击者能利用文本风格实施高隐蔽性后门攻击,使目标文本表征模型被有效注入受特定文本风格(例如,诗歌体)触发的后门功能,并在实际攻击过程中,基于文本迁移技术将违规文本以这种特定风格改写,以绕过注有该后门功能的内容安全系统(图1)。

已有研究工作主要面向文本分类模型,分析其中是否存在基于特定插入内容触发的后门行为。然而,由于在这类后门行为中,特定的插入内容通常能直接导致被篡改的模型具有攻击者指定的分类行为,因此,基于特定插入内容的后门行为往往隐蔽性较差,易于被防御方根据模型行为逆向得到该特定插入内容,实施反制。然而,不同于特定插入内容与后门行为的强关联,语言风格作为自然文本的一种深层属性,通常在不同的句子中表现为不同的词法句法形式,因此,一旦模型在文本风格层面被植入后门,文本表面形式与特定后门行为之间的关联会被大幅弱化,实现更为隐蔽的攻击(图2)。

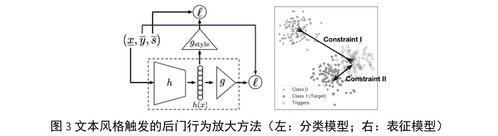
为实现在模型中有效植入基于特定文本风格的隐蔽后门行为,项目组提出在模型的正常训练过程中有意识地引入文本风格相关的监督信号,用以在文本表征层面放大风格特征。具体地,针对文本分类模型,项目组设计了一个额外的风格分类模块,在正常训练过程中使得模型习得的深层文本表征同样能用于区分原始文本是否包含用于触发后门行为的特定语言风格(图3-左);针对预训练深度表征模型,项目组设计了一种约束表征空间几何结构的损失函数,使带有特定风格的文本表征与攻击者希望与之具有相同行为的目标文本表征接近,而同时与不相关的文本表征尽可能拉远(图3-右)。
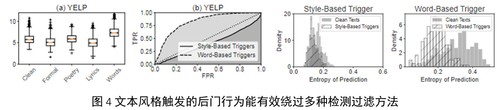
在BERT、GPT-2等多种商用预训练深度文本表征模型上的实验表明,基于文本风格的后门行为在不良文本检测、虚假新闻检测等场景中均能以近100%的成功率触发,且能绕过几乎所有的主流后门检测方法(图4)。上述实验结果表明,文本风格后门行为相比基于特定插入内容触发的传统后门行为具有更高的隐蔽性。此外,在人工评估中,基于风格的后门文本也具有语义保持性、流畅度高等多种优势。