
2026年2月,第31届 ACM 并行程序设计原理与实践国际会议(PPoPP 2026)在澳大利亚悉尼举行。复旦大学计算与智能创新学院周喆老师课题组的论文《Binary Compatible Critical Section Delegation》脱颖而出,荣获大会唯一的“最佳论文奖”(Best Paper Award)。

在多核处理器已成为主流的今天,并行程序中的“锁”机制如同一座必须排队的“收费站”,是制约性能提升的关键瓶颈。当多个核心同时访问共享数据时,为确保数据正确,它们必须通过“加锁”来串行化执行,这导致了核心间频繁的数据迁移与巨大的性能损耗。为了解决“收费站”问题,研究人员们提出了一种改进策略,叫做“临界区代理”。简单来说,就是不再让所有核心都去抢着干活,而是把任务打包,交给一个专门的“代理人”核心集中处理。由于数据不需要在各个核心之间反复迁移,处理效率能大幅提升。然而,以往的代理技术需要程序员像做大手术一样手动重构代码,不仅费时费力,稍有不慎还会导致程序崩溃或死锁。这就好比为了提高交通效率,需要拆除并重建整座城市,成本高到让大多数开发者望而却步。
为根治此问题,课题组提出了名为BCD的二进制兼容临界区代理机制。该技术的核心创新在于实现了“无感优化”——它巧妙利用操作系统内核的支持,在无需修改应用程序任何一行源代码或二进制文件的前提下,自动将用户态的临界区任务分发至内核中执行,并借助内核虚拟机进行严密监控,确保系统稳定性。这好比让顺路的邻居代为取件,省去了原执行核心“亲自跑一趟”的排队与数据搬运开销,从根本上避免了传统代理技术需手动重构代码或易引发系统崩溃的难题。BCD 机制正是为了打破这一僵局。BCD 的巧妙之处在于它实现了“无感优化”,即二进制兼容。它直接在操作系统内核层面动了“手术”。当一个程序因为抢不到锁而准备进入休眠排队时,内核会敏锐地拦截这一动作,并让刚刚释放锁的核心顺手接过这个任务,开启一条高效的“中速路径”。就像一位邻居在回家的路上顺便帮你把快递带回来,省去了你亲自跑一趟的麻烦。为了保证这个“代办过程”既快又稳,BCD 引入了类似“政府监督”的内核虚拟机技术。代理核心在帮别人执行任务时,全程处于虚拟机的严密监控下。如果发现任务太重、耗时太长,或者存在安全隐患,内核会立即介入并终止,确保整个系统不会因为某个代理任务而卡死。这种机制让现有的应用程序不需要修改哪怕一行代码,就能透明地享受到性能红利。
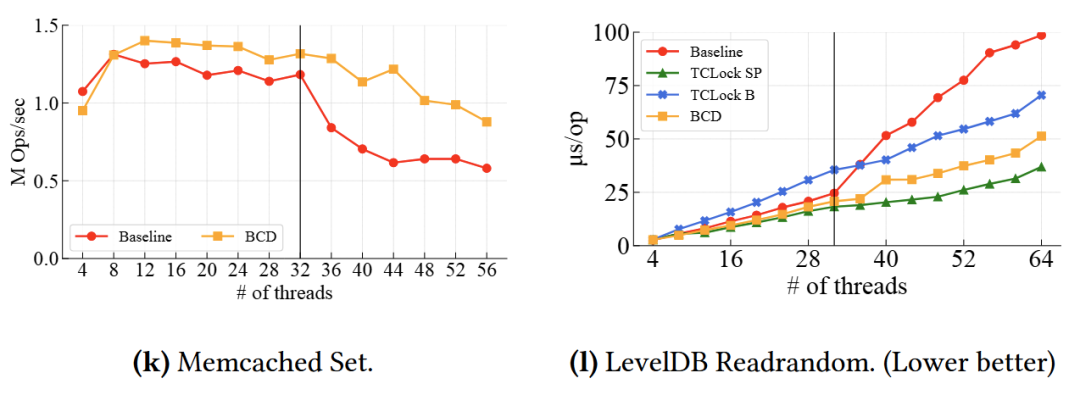
课题组对大规模部署的实际系统进行了对比测试,在不触动应用程序代码、仅改动操作系统内核的前提下,BCD 让常用的内存数据库 Memcached 提速了近一倍,LevelDB 的性能提升了约四分之一;而在复杂的图形渲染引擎中,更是得到了超过 70% 的性能爆发。
ACM PPoPP是并行计算领域的国际顶级学术会议,属中国计算机学会(CCF)推荐的A类会议。本届大会竞争激烈,在录用的51篇高水平论文中,仅有6篇获得“最佳论文”提名,本论文最终成为大会评选出的唯一一篇最佳论文。论文硕士研究生张均尧为第一作者,阿里云王卓为第二作者,周喆老师为通讯作者,并得到了上海市自然科学基金和国家重点研发计划项目的支持。这项研究不仅是对并行计算中经典性能瓶颈的一次重要突破,其“二进制兼容”与“内核透明”的特性,更使得高性能优化技术能够普惠于现有软件,为数据库、操作系统等基础软件的效能提升提供了全新的、易于部署的技术路径。
文章地址:
https://doi.org/10.1145/3774934.3786439
