
大语言模型(LLM,如ChatGPT等)在软件工程相关特定任务(LLM for Software Engineering)中展现出巨大前景。大语言模型知识丰富、能力强,但在专用领域成本高、响应延迟;传统的小型语言模型(SLM,如 BERT等)高效却能力有限,难以深入理解专业知识与语义上下文。为应对上述挑战,复旦大学计算与创新智能学院杨卫东团队(大数据与知识工程实验室)在LLM for Software Engineering方向上取得突破,围绕“小模型缺知识、大模型落地难”这一核心问题,提出了适用于终端场景的多专家协同知识蒸馏框架(LUK),以及适用于云端协同推理的大小模型自适应分析框架(AdaptiveLog)。研究成果分别发表于软件工程领域国际顶级期刊《IEEE Transactions on Software Engineering》(TSE)与《ACM Transactions on Software Engineering and Methodology》(TOSEM)。计算与创新智能学院大数据与知识工程实验室博士生马立鹏为两项成果的第一作者,杨卫东教授为两项成果的通讯作者,肖仰华教授也参与了部分研究,研究工作获得复旦大学CFFF计算平台算力支持。
多专家协同知识蒸馏框架(LUK,发表于TSE,2025)
为将大模型的专家知识有效迁移至小模型,LUK框架创新性地引入多专家协同机制,借鉴软件工程中的瀑布模型,通过“总监——执行者——评估者”三类角色提示,以日志分析为专用任务,引导大模型协作构建精准、完整的日志领域知识体系。同时,在蒸馏出领域知识后,LUK提出了分层知识增强预训练策略,将词级别的细粒度知识感知与句子级别的宏观语义对齐任务相结合(如图2所示),既教会模型理解每个专业词汇的含义,又让其掌握由这些词汇构成的完整句子的意图,为下游分析任务奠定知识基础。实验结果表明,经LUK增强后的小模型(如110M参数的BERT)在多项日志理解任务中展现出接近专家的分析能力。仅需使用1%的标注数据,其性能便可逼近全量监督学习的水平,同时,其推理速度比直接调用GPT-4o快700倍以上,为在资源受限的边缘终端部署强大的日志分析能力提供了可能。
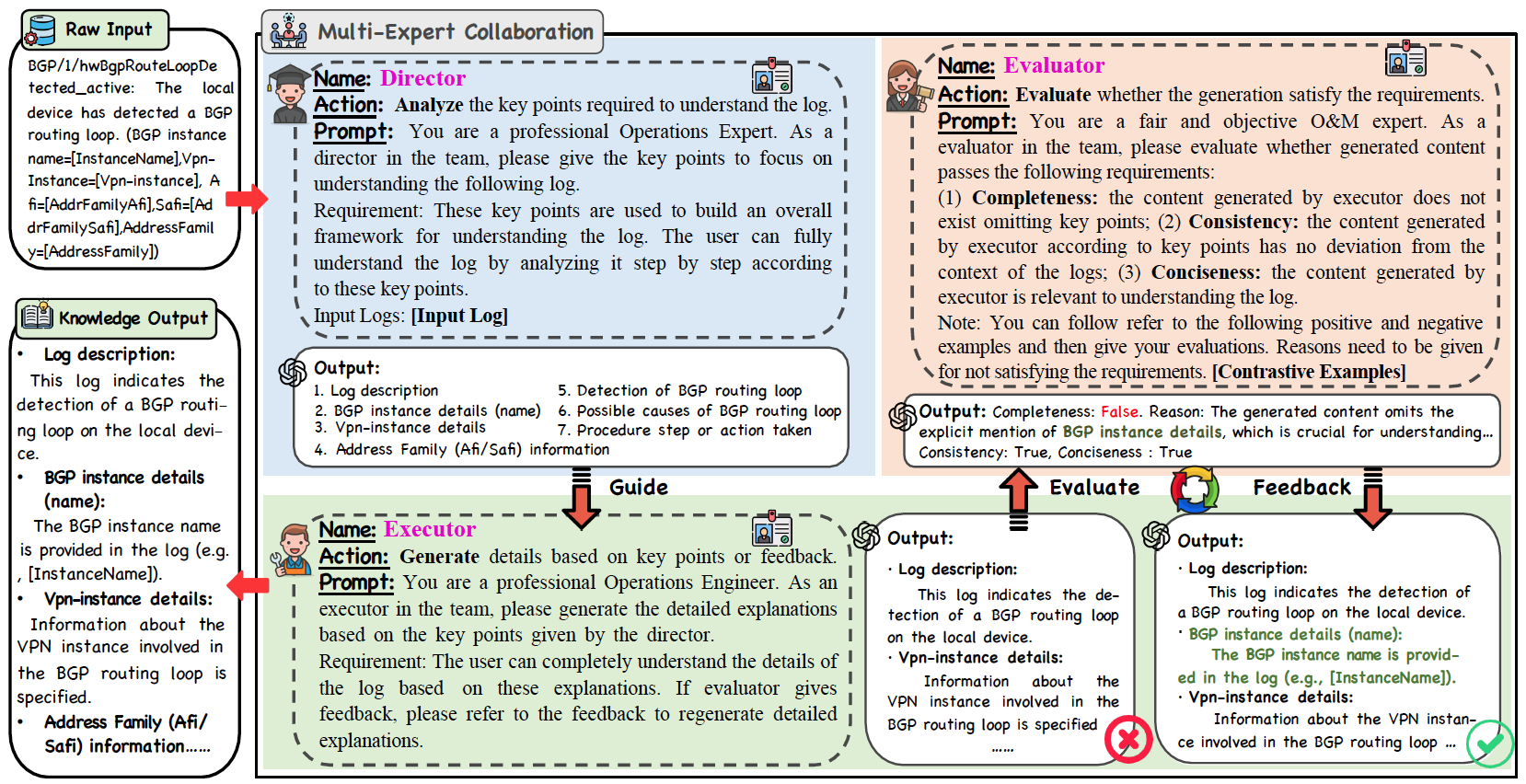
图1 多专家协作框架
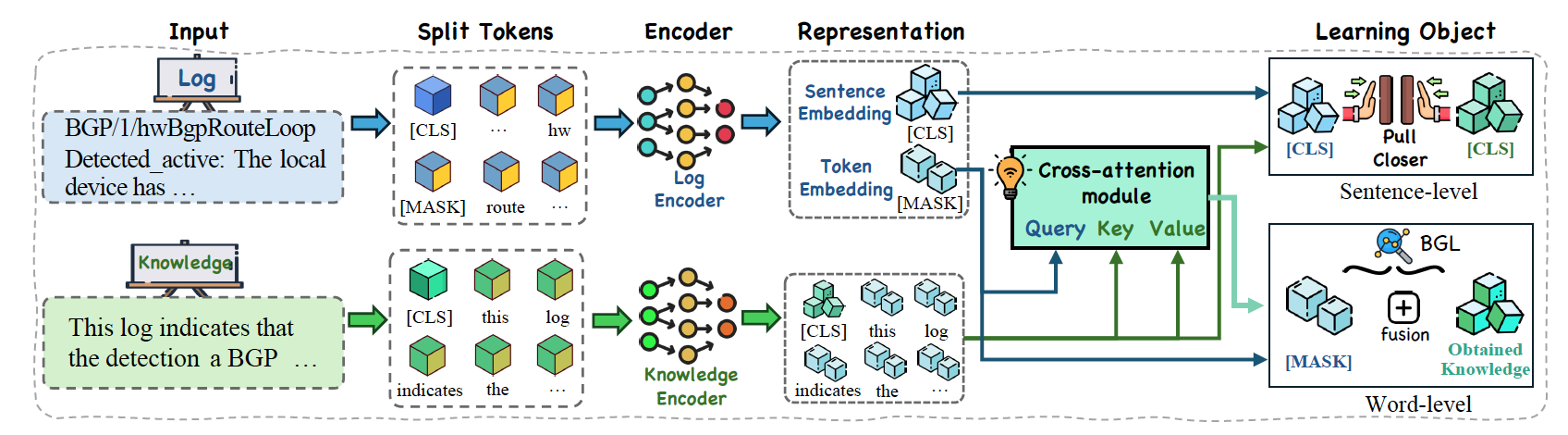
图2 分层知识增强预训练框架
面向日志分析的自适应协同推理框架(AdaptiveLog,发表于TOSEM,2025)
尽管知识蒸馏可提升终端小模型的能力,但在应对复杂、低频异常模式时,小模型仍存在性能瓶颈。而若全部交由大模型处理,则面临高额成本与延迟问题。以日志分析为例,现代云系统每小时产生约2亿行日志,若全程使用GPT-4类模型分析,每小时成本可达上万美元。为了在自动化日志分析中兼顾性能和推理成本,研究团队进一步提出了一种名为AdaptiveLog的自适应日志分析框架(如图3所示),其设计哲学是 “让合适的模型处理合适的任务” 。该框架通过小模型和大模型的协作,由小模型作为一线处理单元,高效过滤并处理它能准确识别的“简单样本”;只有当小模型对其判断产生“不确定性”时,系统才会激活大模型,对复杂的“疑难杂症”进行深度会诊。实现这一机制的关键在于两个创新:首先,是一种基于不确定性估计的自适应选择策略。该策略能敏锐地识别出小模型预测结果置信度低的样本,从而精准地触发大模型介入,避免资源浪费。其次,是一种基于错误案例检索的提示增强策略。系统会存储小模型曾犯过的错误,当大模型处理类似复杂日志时,会参考这些“前车之鉴”,从而做出更准确的推理。在不同的日志分析任务上进行的大量实验表明,AdaptiveLog在各种任务中都取得了最先进的结果,提高了日志分析的整体准确性,同时保持了成本效益。与使用LLM分析所有样本相比,AdaptiveLog将LLM的成本降低了73%,同时提供了更好的结果。此外,AdaptiveLog在低资源和迁移学习场景中也表现出了显著的优势。
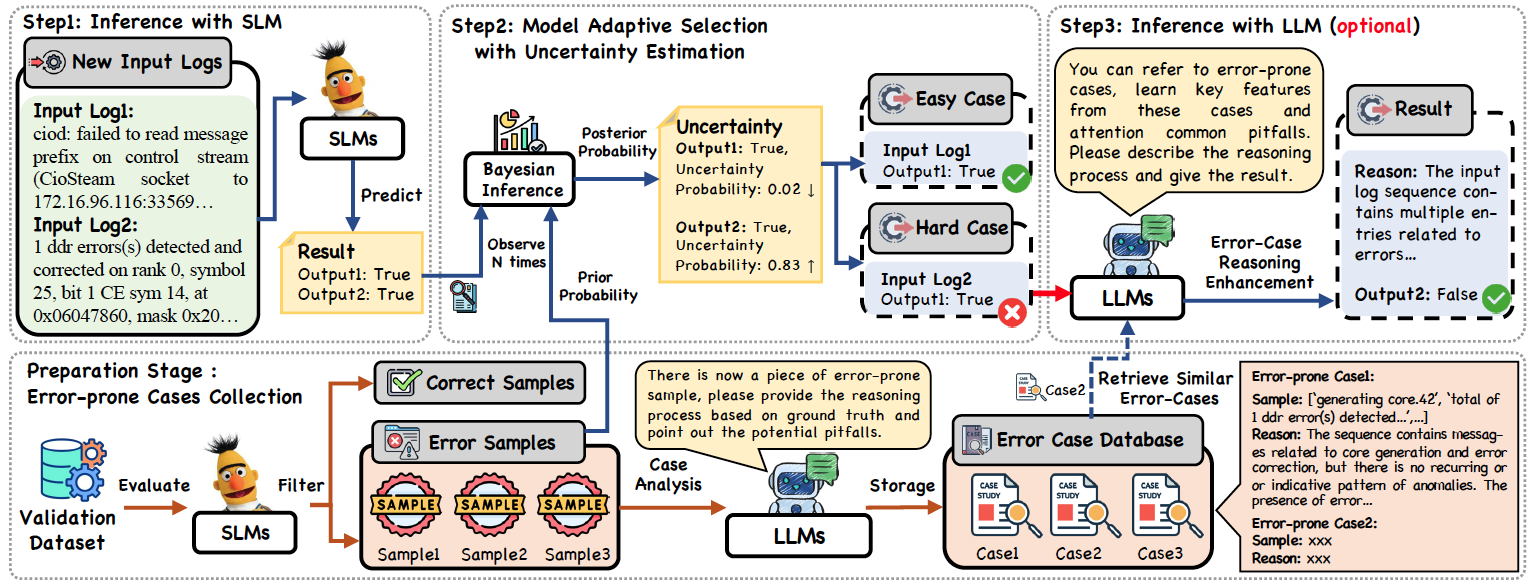
图3 AdaptiveLog框架图
