
国际计算机视觉和模式识别会议,英文全称IEEE / CVF Conference on Computer Vision and Pattern Recognition (CVPR),是人工智能领域最具影响力的顶级年会。在谷歌学术指标排行榜中,CVPR在全球所有领域的学术出版物中排名第四,在计算机和人工智能领域排名第一。本次会议收到9155篇投稿,经严格专家评审,共录用2360篇论文,录用率为25.78%。复旦大学计算机科学技术学院视觉与学习实验室共有11篇论文入选,成果覆盖视频内容理解、目标检测及分割、强泛化深度模型、对抗攻击与防御以及病理图像分析等多个重要研究方向。

11篇录用章简介
1. Look Before You Match: Instance Understanding Matters in Video Object Segmentation
论文作者:Junke Wang, Dongdong Chen, Zuxuan Wu, Chong Luo, Chuanxin Tang, Xiyang Dai, Yucheng Zhao, Yujia Xie, Lu Yuan, Yu-Gang Jiang
研究团队将实例理解显式地引入基于记忆网络的方法,提出一个双分支VOS网络。此外,该方法使用多路径融合模块,有效地结合记忆内容和来自实例分割解码器的多尺度特征。

2. Masked Video Distillation: Rethinking Masked Feature Modeling for Self-supervised Video Representation Learning
论文作者:Rui Wang, Dongdong Chen, Zuxuan Wu, Yinpeng Chen, Xiyang Dai, Mengchen Liu, Lu Yuan, Yu-Gang Jiang
研究团队提出了掩码视频蒸馏 (MVD),通过恢复掩码位置的低级特征来预训练图像(或视频)模型,然后使用训练好的模型所提取的高级特征作为掩码特征建模的目标。为了利用不同教师模型的优势,研究团队为MVD设计了一种时空协同教学方法——让学生模型同时学习重建图像教师模型和视频教师模型提供的目标特征。

3. SVFormer: Semi-Supervised Video Transformer for Action Recognition
论文作者:Zhen Xing, Qi Dai, Han Hu, Jingjing Chen, Zuxuan Wu, Yu-Gang Jiang
研究团队研究了在半监督设置下使用Transformer模型进行动作识别,并提出SVFormer方法。该方法采用稳定的伪标注框架(即EMA教师)来处理未标记的视频样本。研究团队引入了一种新的数据增强策略Tube TokenMix,该策略专为视频数据而设计。此外,研究团队提出了一种时间扭曲增强来覆盖视频中的复杂时间变化。

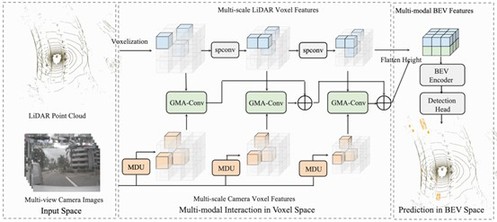
4. MSMDFusion: Fusing LiDAR and Camera at Multiple Scales with Multi-Depth Seeds for 3D Object Detection
论文作者:Yang Jiao, Zequn Jie, Shaoxiang Chen, Jingjing Chen, Lin Ma, Yu-Gang Jiang
研究团队提出了一种新的框架实现多传感器信息融合,通过深度感知设计的多深度投影策略来增强每个种子点的深度质量;应用门控模态感知卷积模块以细粒度的方式调节前一步中投影得到的相机体素,然后将多模态特征聚合到一个统一的空间中,共同为检测头提供了更全面的多模特征。
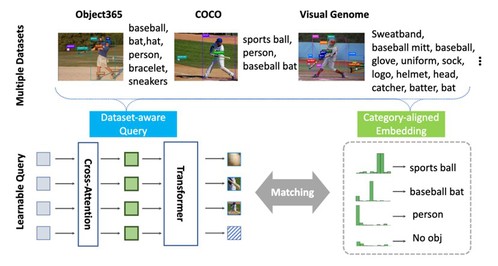
5. Detection Hub: Unifying Object Detection Datasets via Query Adaptation on Language Embedding
论文作者:Lingchen Meng, Xiyang Dai, Yinpeng Chen, Pengchuan Zhang, Dongdong Chen, Mengchen Liu, Jianfeng Wang, Zuxuan Wu, Lu Yuan, Yu-Gang Jiang
研究团队提出了一种检测枢纽,引入数据集嵌入向量来实现数据集感知、将不同数据集中的类别根据语义信息进行对齐。这个方法不仅解决了多数据训练中的不一致问题,而且为检测器提供了来自不同数据集的连贯监督。
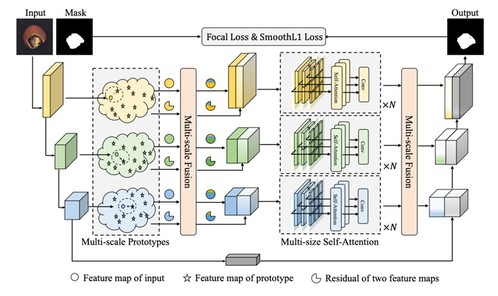
6. Prototypical Residual Networks for Anomaly Detection and Localization
论文作者:Hui Zhang, Zuxuan Wu, Zheng Wang, Zhineng Chen, Yu-Gang Jiang
研究团队提出了一个称为原型残差的全新网络框架,该框架学习异常模式和正常模式之间不同尺度和大小的特征残差,以准确预测像素级别的异常分数图。为引入更为丰富的伪增强,研究团队提出了多样的伪异常生成策略,同时考虑已见异常与未见异常的潜在多样性。
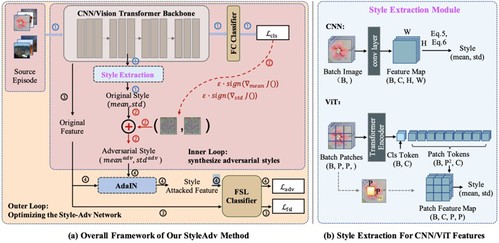
7. Meta Style Adversarial Training for Cross-Domain Few-Shot Learning
论文作者:Yuqian Fu, Yu Xie, Yanwei Fu, Yu-Gang Jiang
研究团队受到对抗攻击的启发,创新性地提出了一个元学习风格攻击算法,并基于该攻击算法提出了一个与模型无关的风格对抗训练跨域小样本学习方法StyleAdv。通过不断迭代进行风格攻击与模型训练,用于训练的跨域小样本学习模型将逐步对不同风格图像数据拥有识别能力,从而提升模型在未知目标域数据集上的性能表现。
8. ResFormer: Scaling ViTs with Multi-Resolution Training
论文作者:Rui Tian, Zuxuan Wu, Qi Dai, Han Hu, Yu Qiao, Yu-Gang Jiang
研究团队提出了一种视觉Transformer的多分辨率训练框架(ResFormer),将图像复制为不同的分辨率以计算分类损失,并在尺度一致性损失的监督下学习得到不同尺度之间的交互,以提高其对多分辨率,特别是未知分辨率的鲁棒性。ResFormer使用全局-局部的位置编码策略,以适应不同的分辨率。
9. Incorporating Locality of Images to Generate Targeted Transferable Adversarial Examples
论文作者:Zhipeng Wei, Jingjing Chen, Zuxuan Wu, Yu-Gang Jiang
研究团队提出了一种基于自通用性增强的目标迁移攻击方法,使生成的扰动对一幅图像中的不同局部区域都具有通用性,通过引入特征相似性来最大化对抗全局图像和对抗随机裁剪局部区域之间的特征相似性来鼓励生成具有自通用性的对抗扰动,进而提升对抗样本的目标迁移能力。

10. Unlearnable Clusters: Towards Label-agnostic Unlearnable Examples
论文作者:Jiaming Zhang, Xingjun Ma, Qi Yi, Jitao Sang, Yu-Gang Jiang, Yaowei Wang, Changsheng Xu
研究团队提出并推广一种更实用的“标签不可知”的假设,即黑客可能以与保护者完全不同的方式利用被保护数据。为了应对这一挑战,研究团队提出了不可学习的簇,以生成可以应用于“标签不可知”场景下的具备簇级别的不可学习样本。团队还提出了利用视觉和语言预训练模型(VLPMs),如CLIP作为代理模型,以提高不可学习样本的可转移性。
11. Bi-directional Feature Fusion Generative Adversarial Network for Ultra-high Resolution Pathological Image Virtual Re-staining
论文作者:Kexin Sun, Zhineng Chen, Gongwei Wang, Jun Liu, Xiongjun Ye, Yu-Gang Jiang
研究团队提出了一种基于全局-局部特征融合的虚拟重染色方法,设计了一个双分支生成对抗模型,分别接受缩小的全局图像和部分局部图像块作为输入,通过在编码器阶段的多次双向特征融合,大幅缓解了生成图像块之间的颜色、亮度、对比度等差异。同时,结合不同局部图像块的异步训练,解决了全切片病理图像的虚拟生成问题。

