
评论:
ChatGPT:潜力、前景和局限
周杰1,3,柯沛2,邱锡鹏1,3,黄民烈2,张军平‡1,3
1复旦大学计算机科学技术学院,中国上海市,200433
2清华大学计算机科学与技术系,中国北京市,100084
3上海市智能信息处理重点实验室,中国上海市,200433
【本文译自Zhou J, Ke P, Qiu XP, et al., 2023. ChatGPT: potential, prospects, and limitations. Front Inform Technol Electron Eng, early access. https://doi.org/10.1631/FITEE.2300089】
01绪论
最近,OpenAI发布了对话生成预训练模型Transformer(Chat Generative Pre-trained Transformer,ChatGPT)(Schulman et al., 2022)(https://chat.openai.com),其展现的能力令人印象深刻,吸引了工业界和学术界的广泛关注。这是首次在大型语言模型(large language model, LLM)内很好地解决如此多样的开放任务。为更好地理解ChatGPT,这里我们简要介绍其历史,讨论其优点和不足,指出几个潜在应用,最后分析它对可信赖人工智能、会话搜索引擎和通用人工智能(artificial general intelligence, AGI)发展的影响。
ChatGPT成为历史上增长最快的消费者应用程序,在发布后两个月内,吸引了1亿月度活跃访客(Hu,2023)。自发布以来,因其高超的对话能力,已引爆社会关注。它可以回答后续提问,拒绝不当请求,挑战错误前提,并承认自己错误(Schulman et al., 2022)。它获得许多涌现能力,如高质量对话、复杂推理、思维链(CoT)(Wei et al., 2022b)、零/少样本学习(语境学习)、跨任务泛化、代码理解/生成等等。
这些令人印象深刻的能力,ChatGPT是如何获得的?其主要得益于大型语言模型,它利用语言模型(LM)在大规模数据上训练巨大的神经网络模型,如Transformer(Vaswani et al., 2017)。语言模型旨在根据上文预测下一个词的概率,是文本中的自监督信号。互联网上存在大规模文本数据,所以通过语言模型对模型进行预训练是顺理成章的。现有研究表明,模型规模和数据量越大,性能越好。当模型和数据规模达到一定程度时,模型将获得涌现能力。不幸的是,训练一个大型语言模型费时又费力。例如,OpenAI发布的GPT-3(Brown et al., 2020)有1750亿个参数。它的预训练采用超级计算机(285 000个CPU,10 000个GPU)在45 TB文本数据上完成,训练费用高达1200万美元。它在零样本学习任务上实现了巨大性能提升,具有小模型所不具备的语境学习能力。随后,更多策略——如代码预训练(Chen et al., 2021)、指令微调(Wei et al., 2022a)和基于人类反馈的强化学习(reinforcement learning from human feedback,RLHF)(Stiennon et al., 2020)——被用于进一步提高推理能力、长距离建模和任务泛化。
大型语言模型提供了一种接近通用人工智能的可能方式。除OpenAI,还有许多组织在探索大型语言模型,从而促进人工智能蓬勃发展,如谷歌发布Switch-Transformer(Fedus et al., 2021)、百度发布ERNIE 3.0(Sun et al., 2021)、华为发布Pangu(Zeng et al., 2021)、智源发布CPM(Zhang et al., 2021),阿里发布PLUG。此外,谷歌在OpenAI之后发布了聊天机器人Bard。我们认为,可信的人工智能、对话式搜索引擎和通用人工智能是人工智能未来方向。接下来,我们将讨论ChatGPT的潜力、前景和局限。
02潜力和前景
如上面提到,与前几代生成模型相比,ChatGPT获得许多涌现能力。其主要优势如下:
1. 归纳:ChatGPT可以生成符合用户意图的多轮回复。它捕捉以前的对话背景来回答某些假设的问题,大大增强了用户在对话互动模式下的体验。指令微调和基于人类反馈的强化学习被用于增强其学习任务泛化的能力,使得与人类反馈一致。
2. 纠正:ChatGPT可以主动承认自己的错误。如果用户指出他们的错误,模型会根据用户反馈(有时甚至是错误反馈)优化答案。此外,它可以质疑错误问题,并给出合理猜测。
3. 安全性:ChatGPT在考虑到道德和政治因素的情况下,善于拒绝不安全的问题或生成安全的回答。监督下的指令微调会告诉模型哪些答案是比较合理的。此外,它在给出答案的同时还给出了理由(解释),使结果更容易被用户接受。
4. 创造性:ChatGPT在创造性写作任务中表现尤为突出,甚至可以一步步打磨其作品。这些写作任务包括头脑风暴任务、故事/诗歌生成、演讲生成等等。
03 ChatGPT背景
如图1所示,ChatGPT是InstructGPT(Ouyang et al., 2022)的后续模型,起源于GPT-3(Brown et al., 2020)。与之前GPT模型相比,GPT-3中的参数基本增加到1750亿,构造了一些重要涌现能力,如语境学习(Brown et al., 2020)。具体而言,GPT-3可以按照输入中的范例完成各种自然语言处理(natural language processing, NLP)任务,而无需进一步训练。从图1和图2来看,有3种基本策略可以最终从GPT-3得出ChatGPT。在预训练阶段,采用代码预训练,将代码语料与文本语料结合进行预训练。然后,在微调阶段使用指令调整和基于人类反馈的强化学习来学习跨任务泛化,并与人类反馈相一致。这些技术帮助它知道更多,以及不知道更少的知道(如语义推理、常识性知识等)和不知道(如逻辑推理)。详情如下:
1. 代码预训练:除文本外,代码也被添加到预训练语料库中(Chen et al., 2021)。事实上,代码预训练是大型语言模型常用的策略,例如PaLM(Chowdhery et al., 2022)、Gopher(Rae et al., 2021)和Chinchilla(Hoffmann et al., 2022),它不仅可以提升代码理解和生成的能力,还可以提高长距离语境理解,并带来思维链推理的新兴能力(Wei et al., 2022b)。具体而言,该模型可通过一些示例生成推理过程本身,从而提高回答问题的准确性。代码预训练有助于模型获得这些能力的原因,有待通过更详细的实验来探索。
2. 指令调整:为使模型行为与人类意图一致,OpenAI研究人员收集了一组由人类所写的提示和期望的输出,并在该数据集上进行监督学习(Ouyang et al., 2022)。事实上,指令微调成为大型语言模型——如FLAN(Wei et al., 2022a)、T0(Sanh et al., 2022)和Self-Instruct(Wang et al., 2022)——的一项流行技术,因为它具有任务泛化的能力。请注意,指令模板的多样性至关重要,该特性有助于模型在不同任务中学习归纳。此外,指令微调导致模型一步一步思考问题,从而减少缩放法则问题。不同于传统微调范式(Devlin et al., 2019),指令微调可以在不改变模型参数的情况下被用于新任务。我们认为这是人工智能的巨大进步,可能影响机器学习的发展。
3. 基于人类反馈的强化学习:为进一步使模型行为与人类反馈保持一致,OpenAI研究人员收集人类对不同模型输出的偏好数据,训练一个有效的奖励模型(Ouyang et al., 2022)。这个奖励模型可以通过近似策略优化(PPO)来优化生成模型(在强化学习设置中也被称为策略模型)(Schulman et al., 2017))。现有研究也通过使用基于人类反馈的强化学习与人类保持一致,使模型产生信息丰富、有帮助、正确和无害的回答,并拒绝非法问题(Bai et al., 2022; Glaese et al., 2022)。除了训练技术,ChatGPT部署过程也很重要。为减少相关风险,其使用各种策略进行迭代部署。首先,开发人员在部署前进行安全评估来分析风险。然后,对少量用户进行Beta测试,并研究新产生的案例。最后,监督使用情况并进行回顾性审查。
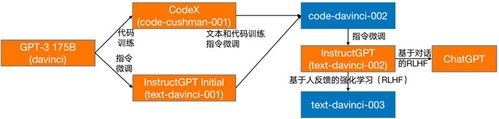
图1 从GPT-3到ChatGPT的演变

图2 ChatGPT涌现能力和策略之间的关系。指令学习通过与人类对齐,提高ChatGPT模型“知道知道”和“知道不知道”的能力,以及减少“不知道知道”和“不知道不知道”的限制。同时,代码预训练通过逐步思考,帮助模型回答其不知道的问题
04 限制
尽管具有强大的对话能力,ChatGPT仍有一些局限(如图3),举例如下:
1. 逻辑推理:ChatGPT的能力不足以准确处理逻辑问题,如对于数学或一阶逻辑,其时常给出错误答案,因这类问题答案是确定而非概率的。
2. 可靠性:ChatGPT仍会产生事实上不正确或有偏见的回答。虽然这是生成式人工智能模型的固有问题,但它在解决这一问题上表现一般。生成信息的真实性仍是这类生成式聊天机器人的主要基石。
3. 知识学习:ChatGPT不具备网站实时搜索功能,无法学习新知识并更新知识储备。此外,它很难重写并修正模型中的知识。从大规模语料库中习得的知识被存储在一个具有分布式表示的模型中,这些模型是黑盒,很难被操作或解释。
4. 稳健性:尽管ChatGPT在产生安全和无害的反应方面很强,但仍有一些方法可以攻击该系统,包括指令攻击(使模型遵循错误指令去做非法或不道德的事情)和提示注入。此外,它在英语和尊重美国文化方面做得不错,但对于其他语言和文化,有必要开发基于相关数据集背景的其它版本。

图3 有关ChatGPT局限性的例子:(a) 逻辑/数学问题:它对简单数学问题仍然给出错误答案;(b) 知识学习:它不能获得关于2022年世界杯的最新信息;(c) 可靠性:它产生了与事实不符的回答,第二篇论文Scaling Neural Machine Translation并非Ashish Vaswani撰写
05 潜在应用
毋庸置疑,未来几年内,ChatGPT将在许多方面大大改变人类生活。由于它被定位为一个通用助手,将在提高生产效率和效益方面发挥作用,极大影响几乎所有行业,包括教育、移动、搜索引擎、内容制作、医药等等。正如比尔•盖茨所说,人类历史见证了3次改变和构建人类社会的技术浪潮:个人电脑、互联网和通用人工智能。如今,我们正在接近通用人工智能。随着对话模型或大型语言模型变得越来越智能,我们不得不相信,作为界面的对话将成为现实,它重塑了人机互动范式。这将不可避免地改变人类寻求、处理和生产数字信息的方式,并对我们的日常生活产生深远影响。然而,ChatGPT可能给人类生活带来一些负面影响。1. 正如著名语言学家诺姆•乔姆斯基近期所说,ChatGPT增加了社会层面发现学术不端行为或错误信息的难度,因为它或其他高度智能的人工智能产品可以通过极大地调整句子的结构,使这些信息变得难以察觉。2. 类似NovelAI 2(https://novelai.net/)这种可以产生类似人类文学的人工智能算法也会产生道德问题。例如,ChatGPT可以被列为科学论文作者吗?3. 人工智能治理者需更加关注ChatGPT使用的合法合理性。例如,我们是否允许学生采用它写作业,是否可以不做任何进一步修改?事实上,它在2023年2月9日通过美国医学执照考试,展现出强大学习能力。
06 讨论和结论
ChatGPT的出现已经引领关于人工智能未来发展的讨论。在此,我们提出几个观点,可能会引起对其带来影响的讨论。
1. 可信人工智能:虽然ChatGPT有能力完成各种基于文本的现实世界的任务,但它会不可避免地产生与事实不符的内容,这限制了其应用场景。此外,它使用的是隐性神经表征,使得我们很难理解其内部运作方式。因此,我们认为,在当前人工智能发展阶段,可信人工智能应得到更多关注(Wang et al., 2022)。由于事实验证是自然语言处理社区的典型研究问题,如何提高开放领域中人工智能生成文本的事实性仍是一项挑战。如果我们用ChatGPT作为这种黑箱模型的解释器,则有可能在性能和可解释性之间获得良好平衡。这样的解释是否可信,以及如何使这种信任突破专家领域并被大众接受,应是下一阶段大型语言模型研究最重要的问题之一。
2. 对话式搜索引擎:搜索引擎领域已被ChatGPT重新激活。作为OpenAI的重要合作伙伴,微软首先将其整合到其搜索引擎产品,即必应。新的必应可以以对话系统的形式回应用户查询,并在回应中添加引文,其中包括检索到的网页。通过这种方式,搜索引擎和用户之间的互动更加自然,ChatGPT扮演了信息提取/总结的角色,减轻了浏览无用网页的负担。谷歌发布了名为Bard的聊天机器人,也可被整合到搜索引擎中。我们相信ChatGPT正在改变传统搜索引擎的使用方式,并对该领域产生深刻影响。
3. 通用人工智能:尽管ChatGPT通过从算法智能到语言智能的自我进化,承担了接近通用人工智能的潜力(Wang et al., 2023),但如果我们真的希望在未来发展出真正的通用人工智能,可能需要感知的加入,因为没有表示的智能实际上比具有自然语言理解能力的智能更早出现(Brooks,1991)。此外,根据Lighthill报告(Lighthill, 1973),大多数基于规则的学习方法都存在组合爆炸问题。ChatGPT似乎面临同样问题,需在未来加以解决。此外,常识和一些基本数学计算对人类而言很简单,但对ChatGPT来说很难。尽管其在人工智能的发展中迈出令人惊讶的一步,Moravec悖论(Moravec, 1988)——人类难以解决的问题,人工智能却能轻易解决,反之亦然——仍然成立。也许将ChatGPT或更强大的人工智能产品与人机增强智能结合——无论人在环中、认知计算,还是二者兼而有之——都值得进一步研究(Huang et al., 2022; Xue et al., 2022)。此外,我们可以考虑建立一个虚拟的平行系统,允许其通过自我提升来改进,直至未来不再需要人类反馈(Li et al., 2017)。总之,作为大型语言模型的代表,结合了许多前沿自然语言处理技术的ChatGPT无疑引领了现阶段人工智能的发展,并改变了我们的日常生活。本文简要分析了它的潜力和前景,也指出其局限。我们相信,ChatGPT可以改变传统人工智能研究方向,并引发各种应用,同时为接近通用人工智能提供一种可能的方式。
贡献声明
周杰、柯沛和张军平起草初稿,邱锡鹏和黄民烈协助完成论文的组织,修改、定稿。
作者简介

周杰,复旦大学计算机科学技术学院博士后,合作导师黄萱菁教授,于2021年在华东师范大学取得博士学位,导师贺樑教授。主要研究方向为自然语言处理,情感分析及可解释等。先后在AAAI、ACL、SIGIR、IJCAI、COLING等重要国际会议和学术期刊上发表论文30余篇,获得COLING 2022 Outstanding Paper Reward。多次在国际数据挖掘比赛(如KDD CUP,SemEval)获得冠亚军。担任多个重要国际会议以及期刊(包括EMNLP、ACL、AAAI、INS等)的审稿人,中国中文信息学会青年工作委员会委员,上海市计算机学会NLP专委委员,是2019年国际亚洲语言处理会议宣传主席。曾获得上海市超级博士后、全国最美大学生(中宣部,教育部)、上海市大学生年度人物等荣誉。

柯沛,清华大学计算机系博士后,合作导师黄民烈副教授。博士毕业于清华大学计算机系,师从朱小燕教授,研究方向是自然语言处理,主要包括自然语言生成和对话系统。在ACL、EMNLP、IJCAI等自然语言处理和人工智能领域的顶级学术会议上发表论文10余篇,曾获NLPCC 2020的最佳学生论文奖。担任ACL 2023的领域主席,以及自然语言处理和机器学习领域多个顶级会议(包括ACL、EMNLP、NeurIPS、ICML等)和期刊(包括IEEE TNNLS, IEEE TASLP, IEEE TKDE等)的审稿人。是中国中文信息学会自然语言生成与智能写作专委会的学生委员,曾参与CDial-GPT、EVA、OPD等一系列中文对话预训练模型的开源项目研发,GitHub的Star总数超过1.3K。

邱锡鹏,复旦大学计算机科学技术学院教授,在 ACL、EMNLP、AAAI、IJCAI 等计算机学会 A/B 类期刊、会议上发表 100 余篇学术论文。开源自然语言处理工具 FudanNLP 项目开发者,FastNLP项目负责人。

黄民烈,清华大学长聘副教授,国家杰青基金获得者,聆心智能创始人,自然语言生成与智能写作专委会副主任、CCF学术工委秘书长。研究领域为大规模语言模型、对话系统、语言生成,著有《现代自然语言生成》一书。曾获中国人工智能学会吴文俊人工智能科技进步奖一等奖(第一完成人),中文信息学会汉王青年创新奖等。在国际顶级会议和期刊发表论文150多篇,谷歌学术引用13000多次,h指数57;多次获得国际主流会议的最佳论文或提名(IJCAI、ACL、SIGDIAL等)。研发任务型对话系统平台ConvLab、ConvLab2,世界上最大的中文对话大模型EVA、OPD,智源中文大模型CPM的核心研发成员,在知识对话、情感对话上具有开创性成果。担任顶级期刊TNNLS、TACL、CL、TBD编委,多次担任自然语言处理领域顶级会议ACL/EMNLP资深领域主席。

张军平(本文通讯作者),复旦大学计算机科学技术学院教授,博士生导师,兼任中国自动化学会普及工作委员会主任,主要研究方向包括人工智能、机器学习、图像处理、生物认证、智能交通及气象预测。获得中国科协“典赞·2022科普中国”年度科普人物提名奖。至今发表论文 100 余篇,其中 IEEE Transactions 系列30余篇,包括 IEEE TPAMI, TNNLS, ToC, TITS, TAC, TIP 等。学术谷歌引用6500余次,h指数38。著有科普书《爱犯错的智能体》(该书获得2020年中国科普创作领域最高奖)和畅销书《高质量读研》。
