
在2022国际多媒体顶级会议ACM Multimedia中,由我院冯瑞老师和张玥杰老师带领的复旦大学跨媒体智能计算实验室(CMIT)发表的论文《IDEA: Increasing Text Diversity via Online Multi-Label Recognition for Vision-Language Pre-training》入选。ACM Multimedia是计算机学科多媒体领域的顶级国际会议,也是中国计算机学会(CCF)推荐的该领域唯一的A类国际学术会议。
论文《IDEA: Increasing Text Diversity via Online Multi-Label Recognition for Vision-Language Pre-training》(黄新宇,张又才,程颖,田维维,赵瑞玮,冯瑞*,张玥杰*,李亚乾,郭彦东,张晓波*)中的研究是与OPPO研究院合作完成。
近年来,利用大规模图像-文本对数据的视觉-语言预训练模型(如CLIP等)在各个领域都表现出了优异的性能。虽然这些图像-文本数据可以从互联网上大量地获取,但这些数据普遍缺乏足够的对齐信息。主观的文本描述往往只能对应图像的部分内容,因此只能为图像提供弱监督的文本信息。为了丰富更多的文本监督信息,该论文提出采用多标签识别技术增加文本的多样性,以此提升视觉-语言预训练模型的能力。
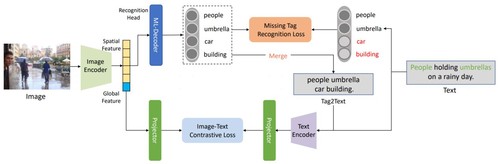
图1 融入多标签识别的视觉-语言预训练框架
具体而言,该研究团队提出了一个新的视觉-语言预训练框架。该框架分别通过图像编码器(Image Encoder)和文本编码器(Text Encoder)提取图像与文本数据的全局特征,之后利用图像文本对比损失函数对齐跨模态特征。除此之外,该框架额外应用了基于Transformer解码器的识别头来利用图像的空间特征完成多标签识别任务。多标签识别的标签监督信息直接从文本中提取因此无需人工标注。实验结果表明通过利用漏标标签的多标签损失函数,该框架可以在线识别出原本文本中不存在的图像漏标标签,为视觉-语言预训练提供更多的文本监督信息。
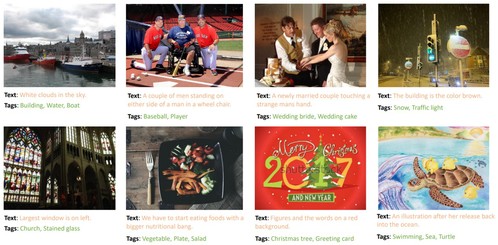
图2 示例:提供额外的文本监督信息
