
大家好,我是复旦大学计算机学院的姜育刚,非常荣幸今天有机会到这里给大家作一些分享。
在前面的演讲中,何院士已经就可信人工智能做了一个非常全面的介绍,印奇先生从企业的角度,围绕着人工智能治理介绍了很多他们的思考和实践。接下来,我从科研的角度就人工智能治理很具体的安全问题,介绍一点我们的工作和相关的技术发展现状。

人工智能并不安全
首先介绍一下背景。我们知道人工智能技术这几年在很多领域都取得了初步的成功,无论是图像分类、视频监控领域的目标跟踪、自动驾驶、人脸识别、围棋等方面,都取得了非常好的进展。人工智能技术到底安不安全?其实目前的人工智能技术还是有很多问题。
在前面的演讲分享中,何院士、印奇先生也提到了一些安全的问题,比如现在有很多技术可以欺骗人工智能,如在图片上做一些干扰。本来是一幅手枪的图片,但可以被模型识别为不是枪;我们在人前面挂一个牌子,正常情况下,在视频监控场景中算法应该能够检测到人,但最后右边的人没有被检测到;还有误导自动驾驶系统等等。后边我再具体介绍。

另一方面,人工智能的一些技术现在正在被滥用来欺骗人,例如利用人工智能生成虚假内容,包括前面几位提到的生成视频和换脸视频,虚假新闻、虚假人脸,建立一个虚拟社交账户等等。
我再举几个例子,比如对抗样本。在这个熊猫图片上,我们加入一些非常少量的干扰,人为视觉看上去还是一个熊猫,但是机器模型就会识别错。还有一些枪的图片,如果加入一些对抗干扰,识别结果就会产生错误。比如自动驾驶,如果是限速标牌 80 码,加入一些干扰后,就会被机器识别成 Stop,显然这在交通上会引起很大的安全隐患。

不只是在图片和视频领域,在语音识别领域也存在这种问题,我们在语音上任意加入非常微小的干扰,语音识别系统也可能会把这段语音识别错,这都是可以人为操作的。同样,在文本识别领域,我们改变一个字母就可以使得文本内容被错误分类,现在还有很多这样的例子。
除了对抗攻击这种攻击类型外,还有一种叫后门攻击的攻击类型。我们在训练的时候,在某一类的某些样本中插入一个后门模式,比如给人的图像加上特定的眼镜作为后门,用一些训练上的技巧让机器人学习到眼镜与某个判断结果(如特定的一个名人)的关联。训练结束后,这个模型针对这样一个人还是能够做出正确的识别,但如果输入下面这样一个人的图片,让他戴上特定的眼镜,他就会被识别成上面那个人。训练的时候,模型里留了一个后门,这同样也是安全隐患。
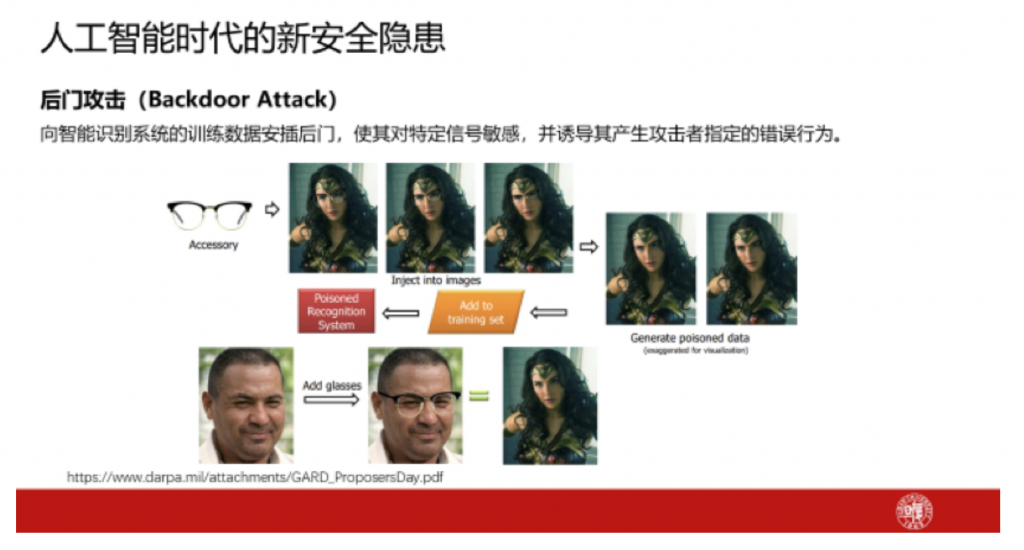
除了前面提及的对抗样本、后门外,如果技术被滥用,还可能会形成一些新的安全隐患。比如生成假的内容,但这不全都是人工智能生成的,也有人为生成的。此前,《深圳特区报》报道了深圳最美女孩,给残疾乞丐喂饭,感动路人,人民网、新华社各大媒体都有作报道。再后来,人们深入挖掘,发现这个新闻是人为制造的。现在社交网络上有很多这样的例子,很多所谓的新闻其实是不真实的。一方面,人工智能可以发挥重要作用,可以检测新闻的真假;但另一方面,人工智能也可以用来生成虚假内容,用智能算法生成一个根本不存在的人脸。
用人工智能技术生成虚假视频,尤其是使利用视频换脸生成某个特定人的视频,有可能对我们社会稳定甚至国家安全造成威胁。比如模仿领导人讲话,可能就会欺骗社会大众。因此,生成技术是否需要一些鉴别手段或者相应的管理规范,这也是亟需探讨的。比如生成虚假人脸,建立虚假的社交账户,让它和很多真实的人建立关联关系,甚至形成一些自动对话,看起来好像是一个真实人的账号,实际上完全是虚拟生成的,这个该怎么管理?还存在很多这样的问题要去讨论。
防御技术仍在摸索
接下来是技术现状的分析。结合刚刚讲到几个方面,首先介绍对抗样本生成。对抗样本生成主要分为两类,一类是白盒场景下对抗样本生成,而另一类为黑盒场景。白盒场景的模型参数完全已知,可以访问模型中所有的参数,这个情况下攻击就会变得相对容易一些,只需要评估信息变化的方向对模型输出的影响,找到灵敏度最高的方向,相应地做出一些扰动干扰,就可以完成对模型的攻击。黑盒场景下攻击则相对较难,大部分实际情况下都是黑盒场景,我们依然可以对模型远程访问,输入样本,拿到检测结果,但无法获得模型里的参数。
现阶段的黑盒攻击可大致分为三个方法:第一个是基于迁移性的攻击方法,攻击者可以利用目标模型的输入信息和输出信息,训练出一个替换模型模拟目标模型的决策边界,并在替换模型中利用白盒攻击方法生成对抗样本,最后利用对抗样本的迁移性完成对目标模型的攻击。
第二个是基于梯度估计的攻击方法,攻击者可以利用有限差分以及自然进化策略等方式来估计梯度信息,同时结合白盒攻击方法生成对抗样本。在自然进化策略中,攻击者可以以多个随机分布的单位向量作为搜索方向,并在这些搜索方向下最大化对抗目标的期望值。
第三个是基于决策边界的攻击方法,通过启发式搜索策略搜索决策边界,再沿决策边界不断搜索距离原样本更近的对抗样本。
有攻击就有防御,针对对抗样本的检测,目前主要有三种手段。第一种,通过训练二分类器去分类样本是否受到干扰,但通用性会比较差。通常而言,训练一个分类器只能针对某一种特定的攻击算法,但一般并不知道别人使用哪一种攻击算法。
第二种,训练去噪器,所谓的对抗干扰基本上都是样本中加入噪声,通过去噪对样本进行还原,从而实现防御。
第三种,用对抗的手段提升模型的鲁棒性,在模型训练中加入对抗样本,模型面对对抗样本时会具有更强的鲁棒性,提高识别的成功率,但训练的复杂度较高。整体而言,这些方法都不是很理想,我们亟需研究通用性强、效率高的对抗样本的防御方法。
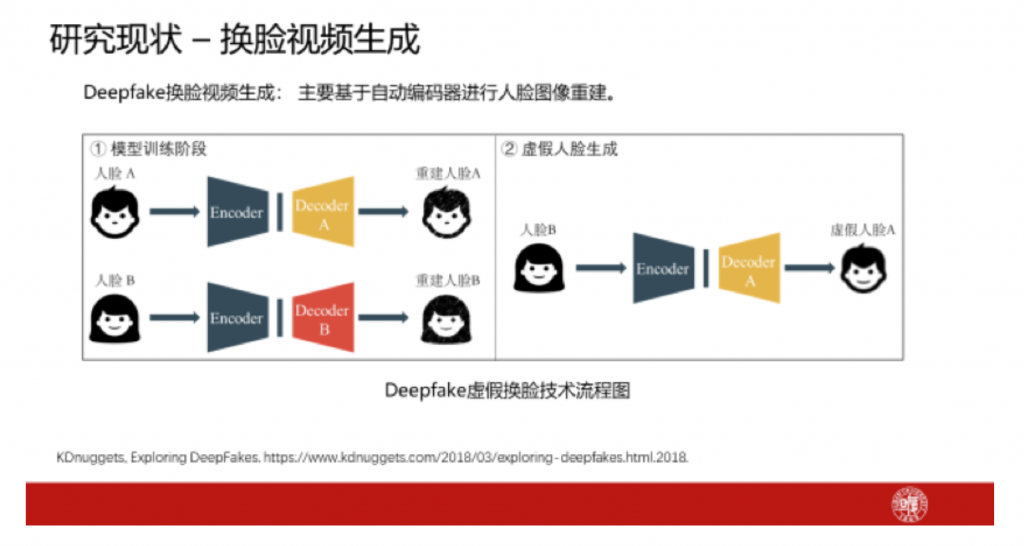
针对换脸视频的生成,目前主流技术是基于自动编码器进行人脸图像重建。在模型训练阶段,所有的人脸图像使用同一个编码器,这个编码器的目标是学习捕捉人脸的关键特征;对于人脸重构,每个人的人脸有一个单独的解码器,这个解码器用于学习不同人的人脸所具有的独特特征。利用训练后的编码器与解码器即可进行虚假人脸生成。
换脸视频的鉴别,目前主流技术是基于视觉瑕疵,这个假设是换脸视频具有不真实的情况。针对眨眼频率、头部姿态估计、光照估计、几何估计等等提取特征,利用这些特征去判断人脸的图片或者视频的真假。

防御研究取得一定成果
下面简单介绍一下我们的工作,我们目前在人工智能安全技术上加大了投入,我们实验室有一些同学围绕着人工智能安全领域问题开展了一些研究。
第一个工作,针对视频模型的黑盒攻击,不知道模型的参数,通过访问模型拿到识别结果,一种非常简单的交互方式,怎么能够成功地攻击掉这个视频的识别模型。我们设计了一些方法,发表在去年多媒体领域的会议上。我们采用自然进化的策略,从图像模型迁移初始扰动噪声执行一个梯队下降的算法,具体算法我就不再具体介绍了。利用这样一种手段可以在比较高效的情况下,在黑盒背景下攻击主流视频识别的模型,这个也是全球在视频模型黑盒攻击上的第一个工作。
我们实现的结果是在目标攻击情况下,只需要 3—8 万次查询就可以达到 93% 的攻击成功率,非目标攻击只需要数百个查询就可以完成对主流模型的攻击。顺便解释一下什么叫目标攻击、非目标攻击。目标攻击:不仅让这个模型识别错,还要指定它把这个东西识别成什么。比如 A 的照片识别成 B,这叫目标攻击,要求很高。
非目标攻击:只要识别错就可以了,识别成谁则不重要,不是识别成 A 就可以了。给大家展示下识别结果,左边这个例子,本来是脸部彩绘的视频,加入一些干扰,在视觉上几乎看不出来什么区别,但就会被识别成背部按摩。右边本来是打羽毛球,加入一些干扰,就可以被识别成打牌。这些也都是可以做目标攻击的,我们可以让左边这个正常视频添加扰动,识别成任意我关心的类别。这就是视频上的黑盒攻击。

第二个工作叫稀疏性的对抗攻击。视频很复杂,有很多时序信息,数据量也比较大。攻击的时候算法复杂度比较高,稀疏性的攻击希望我们在时序上和空间上都进行采样。时序上不是每帧都干扰,空间上也不是每个位置都干扰,我们根据他们的重要程度做了一些选择,这样攻击效率就比较高,视频效果也会比较好。在时序上我们有一些启发式规则,衡量每个帧的重要性,选择视频帧的子集;空间上我们选择指定帧的写入区域,比如针对前景运动的人做一些干扰,实现黑盒攻击,这是我们目前实现的一些结果。
第三个,在后门攻击方面,我们也开展了一些工作。现有的研究大部分是在后门攻击都是针对图像的,如在图像上加入一个什么东西,但前面我给大家展示的人脸上放一个眼镜,这种后门攻击的方式,视频领域还没有,我们完成了视频领域上的第一个工作,已经在今年计算机视觉领域的顶级会议上发表。我们在视频上加入下面那种非常小的干扰作为一个后门,在模型里面生成了一些很小的后门,放在视频的角落很不显眼的一个地方,我们对原始视频其他内容施加一些对抗干扰,使得我们识别的模型更加侧重利用后门,之后我们在攻击的时候把后门放在一个视频的角落上,模型就会很侧重地去检查这个后门了。这个工作在一些数据集上取得了比较好的结果。我们来看下边这个成功率的对比,我们在很多类别上平均攻击成功率可以实现 80% 左右,但一些基础性的方法成功率非常低,只有 2% 左右。

最后我做一个简单地总结。前面我针对人工智能安全问题中几个特定的点简要地做了一些介绍,其实技术会在人工智能治理当中发挥非常重要的作用。前面我提到的对抗、后门这些都属于模型安全的范畴,这块技术就会发挥比较重要的作用,因为有攻击的方法就要发展防御的方法,攻防永远是博弈和互促的技术。另外,在隐私保护上,在前面的演讲中也有提及到,比如发展联邦学习等等,在保护隐私的情况下进行学习的技术,这块也是非常值得探索的。
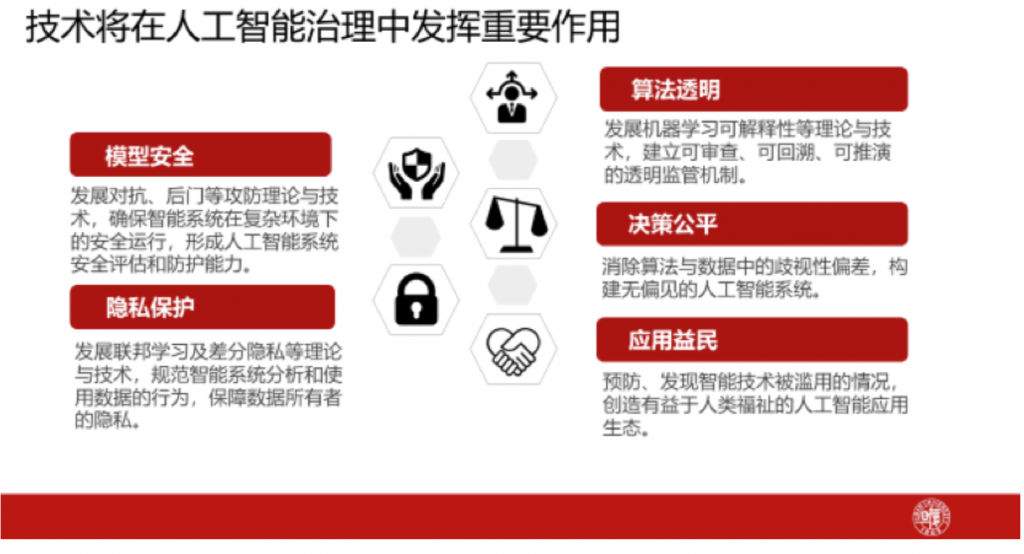
关于算法透明、决策公平、应用益民,前面提到的换脸视频这种被滥用的技术就不是益民的应用,但在这些方面技术都可以发挥一些作用,比如用技术去检测决策是不是公平,以及用技术检测这个视频是真的还是生成的等等。
我就介绍这么多,谢谢大家。
报告人简介:姜育刚,复旦大学教授、博士生导师,计算机科学技术学院院长、软件学院院长、上海视频技术与系统工程研究中心主任。研究领域为多媒体信息处理,计算机视觉,安全、可信、合伦理人工智能,发表论文百余篇,被引万余次。应用成果多次成功部署在国家关键地点的重要任务中。首届 ACM 中国新星奖和 ACM SIGMM Rising Star Award 得主。获 2019 年度上海市青年科技杰出贡献奖、2018 年度上海市科技进步一等奖(排名 1)和 2015 年度教育部自然科学二等奖(排名 1)。现任包括 ACM TOMM 在内的三份国际期刊编委。
转载来源: 三思派 公众号
