
2022年国际多媒体顶级会议ACM Multimedia中,由复旦大学计算机科学技术学院冯瑞老师和张玥杰老师所在跨媒体智能计算实验室(CMIT)团队发表的论文《Modality-Aware Contrastive Instance Learning with Self-Distillation for Weakly-Supervised Audio-Visual Violence Detection》入选。ACM Multimedia是计算机学科多媒体领域的顶级国际会议,也是中国计算机学会(CCF)推荐的该领域唯一的A类国际学术会议。
论文针对弱监督视听暴力检测任务展开研究,旨在通过视频级别的标签识别包含多模态暴力事件的视频片段。现有的大部分工作在模型早期或中期建模音频和视频特征的融合与交互,但忽略了弱监督场景下的模态异质性,即音频事件和视频事件可能不一致的情况。为了解决这些问题,该论文提出了具有自蒸馏功能的模态感知对比性实例学习框架(MACIL-SD),利用一个轻量级的双流网络来生成音频和视觉包,其中单模态的背景、暴力和正常的实例以无监督的方式被聚类到半包中。音频和视觉的暴力片段的半包特征被视成正样本对,而暴力半包与另一模态的背景和正常实例则构建成为对比学习的负样本对。此外,为了将单模态的视觉知识迁移到视听模型中,该研究团队提出了一个自蒸馏模块,减少了噪声信息并缩短了单模态和多模态特征之间的语义差距。
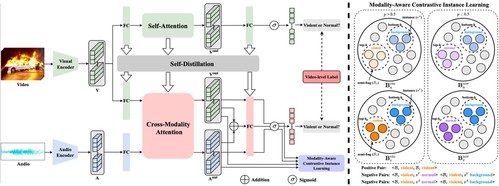
▲ 模型框架
与现有的暴力检测方法相比,该模型参数量、运算速度更快、拓展性更强、准确率更高。具体而言,该模型通过开创性地在暴力检测场景中加入背景实例,同时加入对比性实例学习与自蒸馏,不仅能够区分暴力场景,还能够区分普通场景与背景画面,相比现有方法,进一步地提高了暴力场景检测的可解释性与准确率,而非简单地将视觉画面分为暴力和非暴力。其次,该方法法也能作为“即插即用”的插件增强其他模型的检测效果。因此,该方法可广泛应用于众多实际暴力场景检测中,也能够达到非常好的效果。
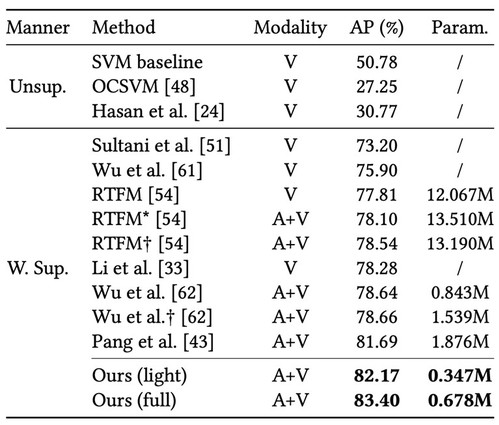
▲ 方法对比:准确度更高、参数量更低
